Measuring Llm Confidence
Measuring LLM Confidence
By: Kevin Madura
kmadura [at] alixpartners [dot] com
Large Language Models (LLMs) have burst into the conversation and have already proven incredibly powerful in accelerating all sorts of knowledge work. Initially explored by the wonderful open source library instructor (and others), the concept of generating structured outputs from unstructured text is an extremely powerful yet simple concept. Think PDF in, Excel out; for example, using a vendor contract as an input, we can quickly extract a row of specific datapoints like contract start date, payment terms, or total price. We would argue it will be one of the, if not the most popular capability used by enterprises.
While this output useful, for production workflows it’s important to quantitatively measure how confident the model is in generating this output so we can respond accordingly. In this post, we explore one approach for doing just that. Specifically, we focus on measuring LLM confidence when using the structured outputs API feature from OpenAI.
The Value Proposition
Pydantic, the de-facto Python library for interfacing with LLMs in a structured way, offers a powerful way to define and enforce data schemas using Python type annotations. Pioneered by instructor, we extend this concept to allow non-technical users to define business-critial datapoints to extract from source data. We do this by modeling them in Pydantic and allowing the LLM to populate the final template.
By a.) ensuring the output types match what we expect (i.e., schema validation) and b.) measuring confidence of the LLM at a field-level, we can:
- Ensure data consistency across different parts of our workflow
- Identify potential errors quickly, to “offramp” to human reviewers
- Enable automated decision-making based on confidence thresholds
- Provide transparency into the model’s decision-making process
- Facilitate easier debugging and maintenance
While LLMs typically don’t provide straightforward confidence metrics like traditional ML models, we can derive meaningful confidence measures by analyzing certain information provided by the model and API response.
Approach
As you may know, LLMs operate on “tokens” - tokens are the fundamental units of text used for processing and understanding language. These tokens can be individual words, subwords, or even characters, and they enable the model to analyze and generate human language by breaking down text into manageable, interpretable pieces.
When LLMs generate text, they are iteratively choosing the most likely next token based on their training data. This process involves calculating probabilities - often referred to as log-probabilities (“logprobs”) - for the next sequence of characters. When using the OpenAI API, you can specify whether you want the more detailed logprobs information in the API response by setting logprobs = True.
The resulting array can be used to evaluate how confident the model was in generating certain aspects of its answer. However, even when using structured outputs, we get logprobs for the entire sequence, including JSON characters, instead of just the fields themselves.
While useful, this doesn’t provide insights into which fields of the output the model is uncertain about. Inspiried in part by Will Kurt from .txt engineering, we “skip” the JSON characters when iterating through the logprobs object. Put simply, we attempt to align each element of the logprobs array with the resulting Pydantic model in order to collect the logprobs for each field. We use this to more precisely measure confidence for each Pydantic field. We then update the final Pydantic model with an additional property: that field’s confidence. Importantly, we convert from an untuitive logprobs value (which is a negative number) to a percentage confidence (0 - 100%) which is easier to reason about for non-technical users1.
Code Walkthrough
We provide below an excerpt of the code to do this. In short, we treat the logprobs output as a “stream,” attempting to match the corresponding tokens in the logprobs array with values from the Pydantic model produced by the API. We consume tokens in the stream to ensure no double-counting or mismatches.
An excerpt of the stream logic is shown below:
def match_value(self, value: Any) -> Optional[TokenMatch]:
"""
Match a value (which can be bool, str, etc.) and return the corresponding tokens and logprobs.
"""
if isinstance(value, bool):
# Convert to string, in order to tokenize
value_str = "true" if value else "false"
# Tokenize the value
target_tokens = tokenize_value(value_str)
print(f"Attempting to match boolean value: {value_str} with tokens {target_tokens}")
return self.find_sequence(target_tokens)
elif isinstance(value, str):
# Tokenize the value; straightforward in this case, as it is a string
target_tokens = tokenize_value(value)
print(f"Attempting to match string value: {value} with tokens {target_tokens}")
return self.find_sequence(target_tokens)
# ... continue for other data types ...
match_value is part of a class which coordinates objects and reulsting matches; find_sequence is the function which actually performs the reconciliation and tracks token consumption. tokenize_value() is a simple call to tiktoken using o200k_base, since we use OpenAI’s gpt-4o for this excercise
After the consuming and matching step, we calculate the various property values we care about: average logprob, the more-intuitive probabilty value, and other potentially useful information such as the position in the input string:
class ConfidenceAnalyzer:
def __init__(self, completion_response: Any, encoding_name: str = "o200k_base"):
logprobs_content = completion_response.choices[0].logprobs.content
self.tokens = [t.token.replace('Ġ', '').replace('▁', '') for t in logprobs_content]
self.logprobs = [t.logprob for t in logprobs_content]
self.stream = TokenStream(self.tokens, self.logprobs)
def analyze(self, pydantic_obj: BaseModel) -> tuple[List[Dict[str, Any]], BaseModel]:
results = []
json_str = pydantic_obj.model_dump_json()
json_obj = json.loads(json_str)
field_paths = self.flatten_json(json_obj)
for field_path, value in sorted(field_paths.items()):
match = self.stream.match_value(value)
if match:
total_logprob = sum(match.logprobs)
probability = math.exp(total_logprob) * 100
avg_logprob = total_logprob / len(match.logprobs)
results.append({
'field': field_path,
'value': value,
'position': match.position,
'avg_logprob': avg_logprob,
'probability': f"{probability:.2f}%"
})
enhanced_model = convert_to_confidence_model(pydantic_obj, results)
return results, enhanced_model
There’s a bit more scaffolding and processing done, but fundamentally, that’s it. Simply align the logprobs output with the JSON string, and calculate the logprobs for only the JSON field values.
Practical Implementation
Let’s examine a complete example that shows what an output might look:
from openai import OpenAI
from pydantic import BaseModel, EmailStr
# Define the base schema
class UserProfile(BaseModel):
name: str
age: int
email: EmailStr
# Get the output from the OpenAI API
async def get_oai_output(sys_msg: str, user_msg: str, model: BaseModel):
client = OpenAI(
api_key="XXXX",
api_version="2024-08-06"
)
messages = [
{
"role": "system",
"content": sys_msg,
"type": "text"
},
{
"role": "user",
"content": user_msg,
"type": "text"
},
]
completion = await client.beta.chat.completions.parse(
model="gpt-4o",
messages=messages,
response_format=model,
# Importantly, we ask for the `logprobs` value in the response!
logprobs=True,
top_logprobs=1
)
return completion.choices[0].message.parsed
# Example usage
response = get_oai_output(
"Extract the specified data"
, "John Doe is 32 years old, with the mail address of john@example.com"
, UserProfile
)
results_raw, result_model = analyze_completion(completion, response)
# Returns a tuple
print(result_model.model_dump_json(indent=2))
This produces a the structured output – with our newly calculated confidence metrics:
{
"name": {
"value": "John Doe",
"confidence": {
"logprob": -1.9563835050000002e-6,
"probability": "100%",
"position": 4
}
},
"age": {
"value": 32,
"confidence": {
"logprob": -0.027487222,
"probability": "97.29%",
"position": 7
}
},
"email": {
"value": "john@example.com",
"confidence": {
"logprob": -0.000972158425925,
"probability": "99.90%",
"position": 9
}
}
}
Advantages & Limitations
Exposing the LLM’s confidence in an intuitive way offers numerous advantages.
- Better understanding: Offer non-technical users a better way to understand the systems they’re working with.
- Measurability: Better measure the model’s weakpoints to employ additional methods, such as LLM-as-a-Judge, self-correction, or even manual review.
- Error Localization: Quickly identify and correct specific inaccuracies in the LLM output.
However, there are real limitations that are left as an exercise for the reader. In particular, the length of the generated content has a material impact on the probability output. A longer string of tokens will naturally have a lower average logprobs than a field with a single token value, leading to a lesser confidence score.
As an example, in the extraction below, the service field is specified as an open-ended str field for the LLM to populate. Because this can be entire sentences, the LLM generates more tokens, which negatively impacts the confidence score as more logprobs are accrued. In contrast, firm_name or invoice_date are typically less than 5 tokens, leading to a much higher confidence. This means that, in the ‘naive implementation’ shown above, confidence can only be measured on a relative basis - i.e., service isn’t necessarily comparable to invoice_number and should have its own threshold for further review.
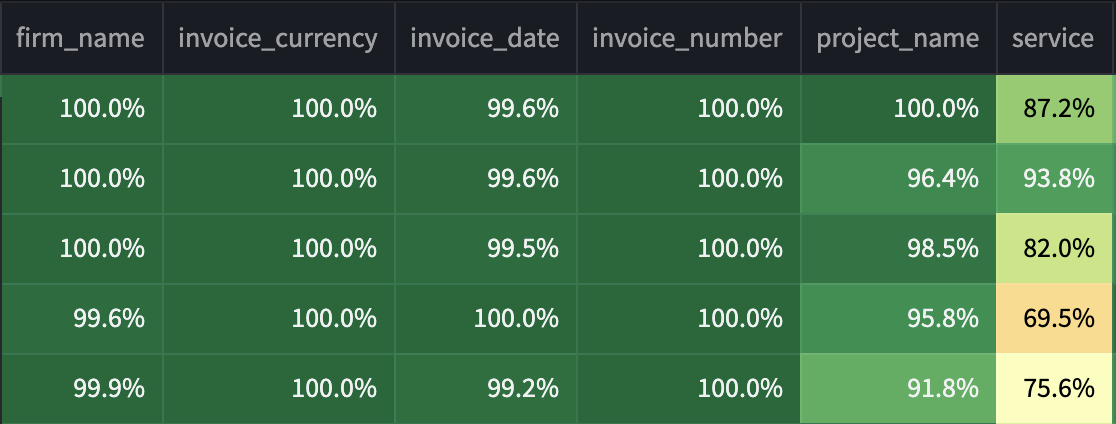
To address this, we have developed thresholds for different field types - e.g., boolean fields are treated much differently than long-form str fields. We continue to explore these thresholds for longer-form fields.
Conclusion
While this methodology will surely make it into a future API release, we wanted to share thoughts on how we are experimenting with these new and powerful technologies.
As LLMs continue to permeate various aspects of work, ensuring the accuracy and reliability of their outputs becomes increasingly important. By giving users, developers and data scientists a more nuanced understanding of LLM performance and confidence, we can build more robust and trustworthy applications.
-
This is calcuated by performing the following:
math.exp(sum(logprob)) * 100↩